个人简介 Short Bio
目前正在山东大学控制科学与工程学院攻读博士学位, 研究方向语言引导的机器人目标分割与抓取姿态估计.
I am studying for a PhD in the School of Control Science and Engineering of Shandong University, researching language-conditioned robot object image segmentation and grasp pose estimation.
在生活中,我尝试做一名冒险家,目前对徒步、露营、土坡车、健身、养宠物感兴趣,喜欢通过相机记录自己生活的点点滴滴,希望抓住最后这一点快乐的读书时光和为数不多的青春,多尝试不一样的东西。
In life, I am an adventurer, currently trying hiking, camping, dirty jumping in mountain biking, fitness, pet and other activities. I like to capture the little moments of my life through my camera, hoping to seize these last joyful moments of my student days and the fleeting youth to try as many different things as possible.
感兴趣领域 Interests
服务机器人
Service Robots大模型
Large Language Model多模态
Multimodaity人机交互
Human-Robot Interaction具身操作
Embodied Manipulation计算机视觉
Computer Vision
教育经历 Education
- 2015年9月-2019年6月:杭州电子科技大学自动化学院获得学士学位
September 2015 - June 2019: B.S. Degree from School of Automation, Hangzhou Dianzi University - 2022年7月-2022年9月:俄罗斯ITMO大学控制系统与机器人国际夏令营
July 2022 - September 2022: International Summer School for Control Systems and Robotics, ITMO University, Russia - 2019年9月-2022年6月:杭州电子科技大学自动化学院获得硕士学位
September 2019 - June 2022: M.S. degree from School of Automation, Hangzhou Dianzi University
学术论文 Publications
- J. Xie, J. Liu, Z. Zhu, C. Wang, P. Duan and F. Zhou, “Infusing Multisource Heterogeneous Knowledge for Language-Conditioned Segmentation and Grasping,” in IEEE Transactions on Instrumentation and Measurement, vol. 73, pp. 1-11, 2024.
- J. Xie, J. Liu, S. Huang, C. Wang and F. Zhou, “Listen, Perceive, Grasp: CLIP-Driven Attribute-Aware Network for Language-Conditioned Visual Segmentation and Grasping,” in IEEE Transactions on Automation Science and Engineering, doi: 10.1109/TASE.2024.3510777.
- Xie J, Liu J, Wang G, et al. SATR: Semantics-Aware Triadic Refinement network for referring image segmentation[J]. Knowledge-Based Systems, 2024, 284: 111243.
- J. Xie, F. Zhou, J. Liu and C. Wang, “Semi-Supervised Language-Conditioned Grasping With Curriculum-Scheduled Augmentation and Geometric Consistency,” in IEEE Robotics and Automation Letters, vol. 10, no. 4, pp. 4021-4028.
- Xie J, Zhang B, Lu Q, et al. A Dynamic Head Gesture Recognition Method for Real-time Intention Inference and Its Application to Visual Human-robot Interaction[J]. International Journal of Control, Automation and Systems, 2024, 22(1): 252-264.
- 谢佳龙,张波涛,吕强.一种基于双流融合3D卷积神经网络的动态头势识别方法[J].电子学报,2021,49(07):1363-1369.
- J. Liu, J. Xie, L. Xiao, C. Wang and F. Zhou, “Hierarchical Multi-Modal Fusion for Language-Conditioned Robotic Grasping Detection in Clutter,” in IEEE Robotics and Automation Letters, vol. 9, no. 10, pp. 8762-8769.
- J. Liu, J. Xie, S. Huang, C. Wang and F. Zhou, “Continual Learning for Robotic Grasping Detection With Knowledge Transferring,” in IEEE Transactions on Industrial Electronics, vol. 71, no. 9, pp. 11019-11027..
- J. Liu, J. Xie, F. Zhou and S. He, “Question Type-Aware Debiasing for Test-Time Visual Question Answering Model Adaptation,” in IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 11, pp. 10805-10816, Nov. 2024.
- Liu J, Xie J L, Zhou F, et al. Triadic temporal-semantic alignment for weakly-supervised video moment retrieval[J]. Pattern Recognition, 2024, 156: 110819.
项目经历 Project Experience
山东省重点研发计划(乡村振兴科技创新提振行动计划)项目:宜居宜业和美乡村关键技术集成与综合应用示范(2023TZXD018), 2023.9 - 2026.8.
负责视觉-语言图像目标分割与机器人抓取姿态估计,主要完成项目多模态感知:
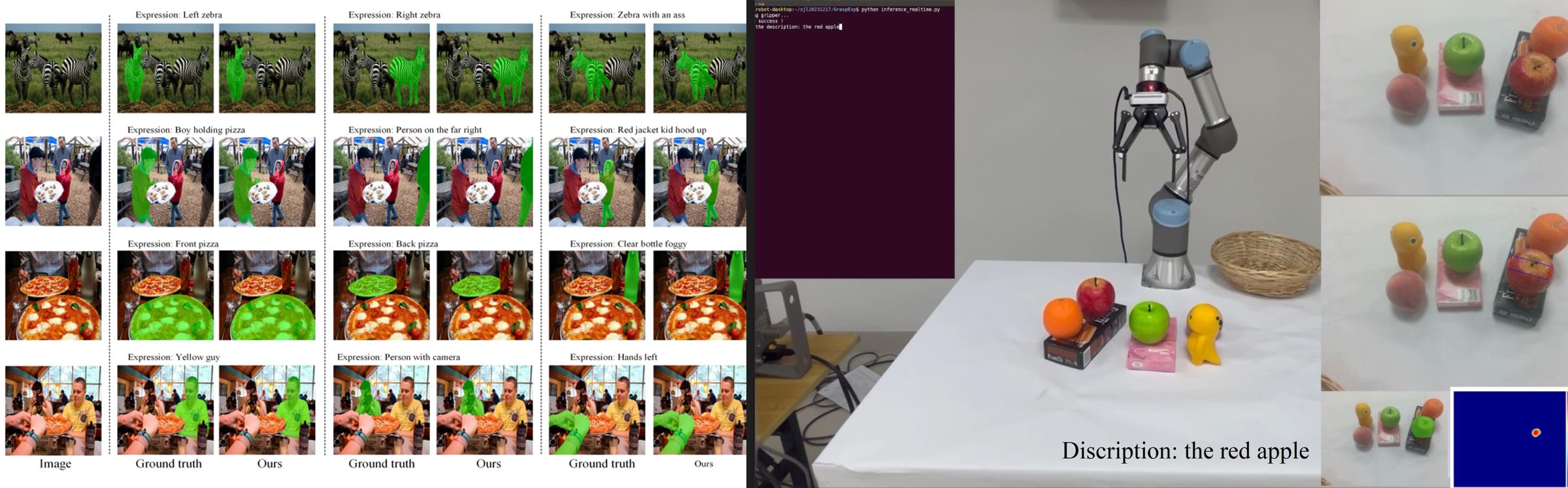
(1)设计指代目标图像分割模型,使用Swin Transformer做视觉编码器、RoBERTa做语言编码器,设计语言引导的像素解析模块,在Swin Transformer中实现语言特征融入,结合边界、细节与显著特征实现三元特征融合,构建多任务训练损失;
(2)微调CLIP模型作为视觉与文本编码器,实现复杂场景下隐式文本-图像对齐特征提取,通过GPT-4生成实体常识知识并设计异构多源知识融合策略,构建高精细度解码器结构,实现混乱场景下的多模态感知。
(3)为提高少量语言-视觉数据训练的有效性,构建基于课程学习计划的数据增强方案,设计学生-教师知识蒸馏网络,并构建视觉几何一致性正则策略。相关工作整理论文4篇。
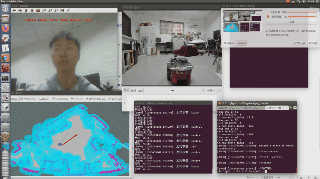
美团机器人研究院科研合作项目:基于具身智能的混乱场景自适应持续抓取方法研究, 2024.3 - 2025.3.
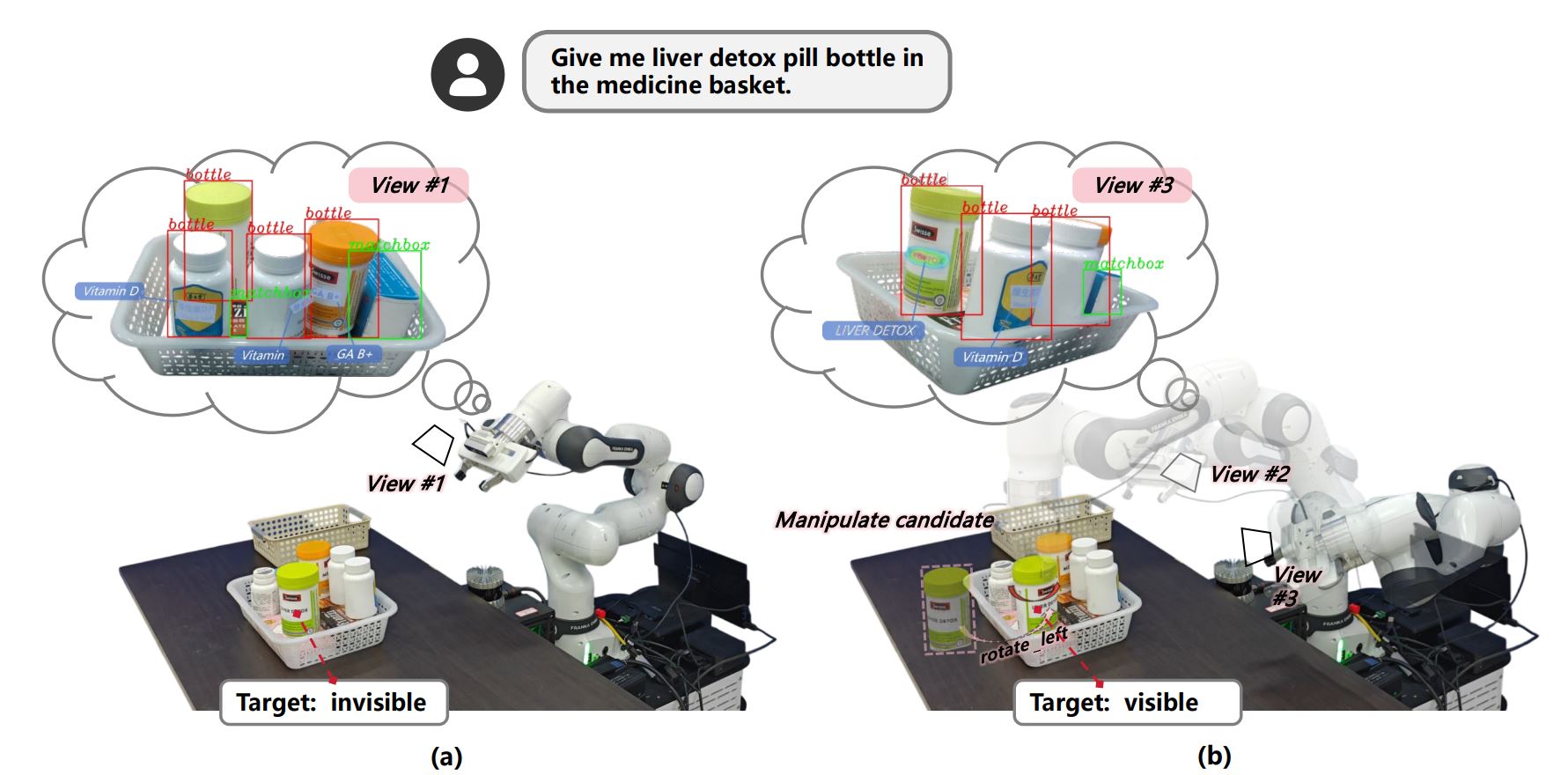
主要负责基于大模型的机器人行为控制与决策代码生成,主要完成构建大模型-机器人结合的Agent框架,使用GPT-4作为大模型基础构建Prompt工程,将机器人感知信息(目标位置、语音指令等)作为动态输入Prompt、定义机器人API手册作为Tool-Use Prompt并迭代选择Top-K个优秀历史行为数据作为CoT与Memory Prompt,使用GPT-4补充感知目标的常识知识信息并构建场景知识图谱,实现机器人在目标遮挡下的细粒度信息感知和自主目标探索。相关成果整理成了论文1篇。
济南市“新高校20 条”资助科研带头人工作室项目:机器人超融合云服务平台实用化关键技术研究(2021GXRC079), 2022.1.1 - 2024.12.31.
主要负责基于ChatGLM的服务机器人故障诊断问答系统构建,完成设计服务机器人云平台故障诊断智能助手,构建用于的SFT和RLHF阶段的基于Alapace格式的服务机器人故障-问题数据集,并基于GPT-4进行优化和拓展数据集,使用ChatGLM3-6B作为基础大模型,在LLaMA-Fractory平台上对其进行LoRA微调和DPO对齐,实现了服务机器人故障诊断智能问答系统。

浙江省重点研发计划项目:面向养老助残任务的刚-柔-软集成协作机器人设计及智能控制(2019C04018), 2019.9 - 2022.9
负责视频动作识别与基于人类反馈的机器人决策生成方案设计,主要实现视频分析与个性化交互算法设计:
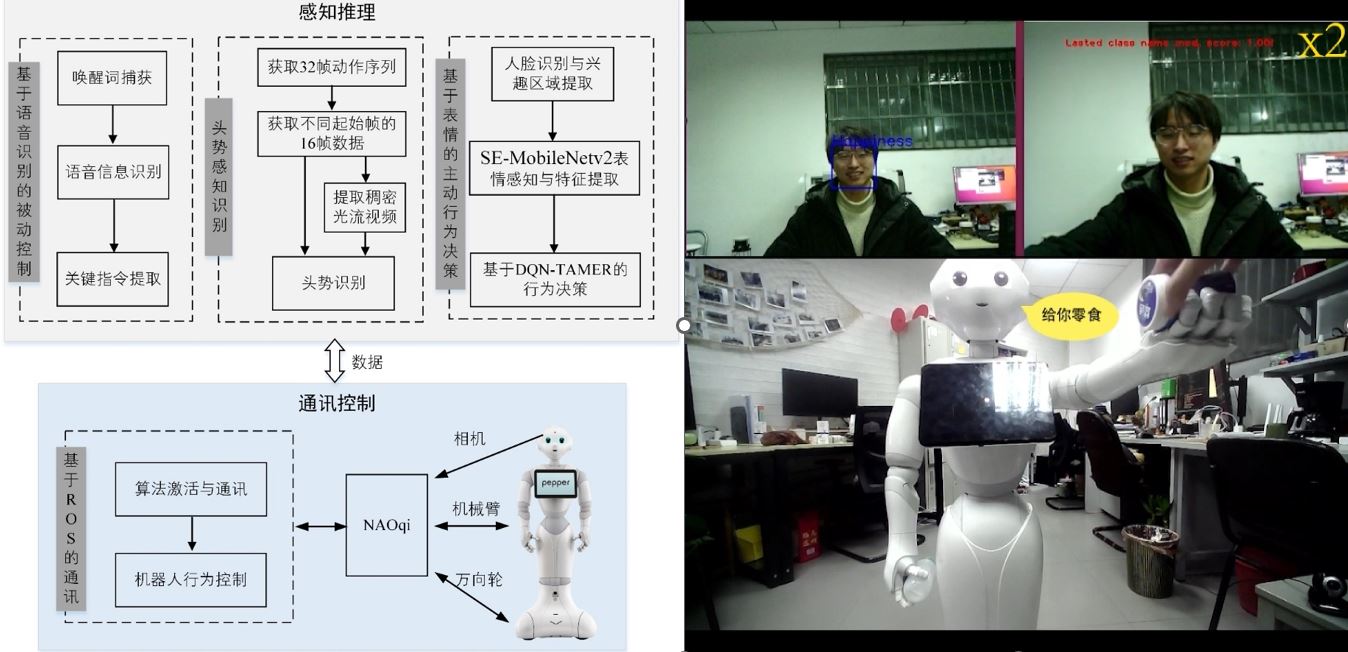
(1)设计基于视频流的动态头势识别算法,基于Tensorflow构建双流3DCNN网络,实现视频流下的实时动态头势识别,并部署在RTX3060服务器与英伟达Jetson TX2开发板;
(2)使用头势识别与表情识别作为显式和隐式的奖励函数模型,使用机器人行为模型作为动作空间,通过人类情感反馈训练DQN模型,实现了机器人主动和被动地做出服务决策。相关工作整理成论文2篇。
企业合作项目:无人驾驶汽车模拟系统开发, 2020.12 - 2021.6.
负责无人驾驶感知决策方法开发,主要实现:
(1)基于松灵底盘搭建无人驾驶平台,基于ROS实现Intel NUC工控机与英伟达Jetson Xavier的双机通讯,其中NUC实现数据采集与预处理,Xavier实现视觉模型推理;
(2)基于YOLO实现红绿灯、行人等目标数据采集与微调,并在Xavier和ROS进行部署(3)基于C++完成车道线检测,并利用PID、KCF和卡尔曼滤波算法实现车道线跟踪。

实习经历 Intern Experience
阿里巴巴菜鸟集团:自动驾驶大模型算法工程师
(1)跟进最新自动驾驶VLA模型,复现OmniDrive、Orion等VLA架构
(2)搭建Nuscenes、Bench2Drive等自动驾驶开环和闭环测试环境
(3)设计基于LLM(VLM)-Diffusion融合架构的VLA模型(提升实时性),针对图像、文本、车辆状态等多模态数据,基于Qwen-3B设计多行为专家的MoE架构行为推理架构,基于不同场景下自适应思维链行为推理方案设计,设计基于diffusion架构的驾驶多模轨迹生成

荣誉与奖励 Honors and Award
- 第十七届全国数学建模三等奖 2020年
- 第十七届浙江省挑战杯三等奖 2021年
- 杭州电子科技大学优秀毕业生 2022年
- 第五届全国人工智能创新大赛一等奖 2023年
- 第六届全国人工智能创新大赛三等奖 2024年
- 第十九届电子设计竞赛初赛二等奖 2024年
- 比亚迪学业奖学金 2024年
- 2024年度优秀研究生
进一步了解我 About
- Github: https://github.com/xiejialong
- Bilibili: https://space.bilibili.com/286191903
- CSDN:https://blog.csdn.net/Jolen_xie
- Eamil: jolen_xie@qq.com
- 抖音号: BeOptimistic.Xie